Dynamic Scraper for Financial Planners: Leveraging BeautifulSoup and Playwright
In this project we leverage BeautifulSoup and Playwright to extract contact information for Financial Planners from www.plannersearch.org that meet specific criteria.
Project Overview
- Introduction: In the rapidly evolving world of financial planning, access to up-to-date and accurate data is crucial. This project addresses the challenge of extracting detailed contact information of top-tier Financial Planners, a task vital for market analysis and strategic outreach. By leveraging advanced web scraping technologies, we aim to streamline the process of gathering this essential data.
- Problem Statement: To accurately scrape contact information for Financial Planners listed on www.plannersearch.org. The Financial Planners must be responsible for investable assets over $1,000,000. Scraping data from a site such as this includes a number of challenges, including dynamic content, infinite scroll, and specific search criteria.
- Solution: Our Python script will navigate to the correct URL, automate the proper search terms, and extract the required fields for each planner. The script will manage the "infinite scroll" style site, and all information we be output to a CSV file.
- Technologies Used: For this project, we chose Beautiful Soup and Playwright for their distinct capabilities. Beautiful Soup excels in parsing HTML documents, making it ideal for extracting specific data from complex web pages. Playwright, on the other hand, is adept at automating browser interactions, crucial for navigating through the website’s dynamic content and infinite scroll. Together, they form a powerful duo that can efficiently handle both the extraction and interaction aspects of web scraping.
Key Features
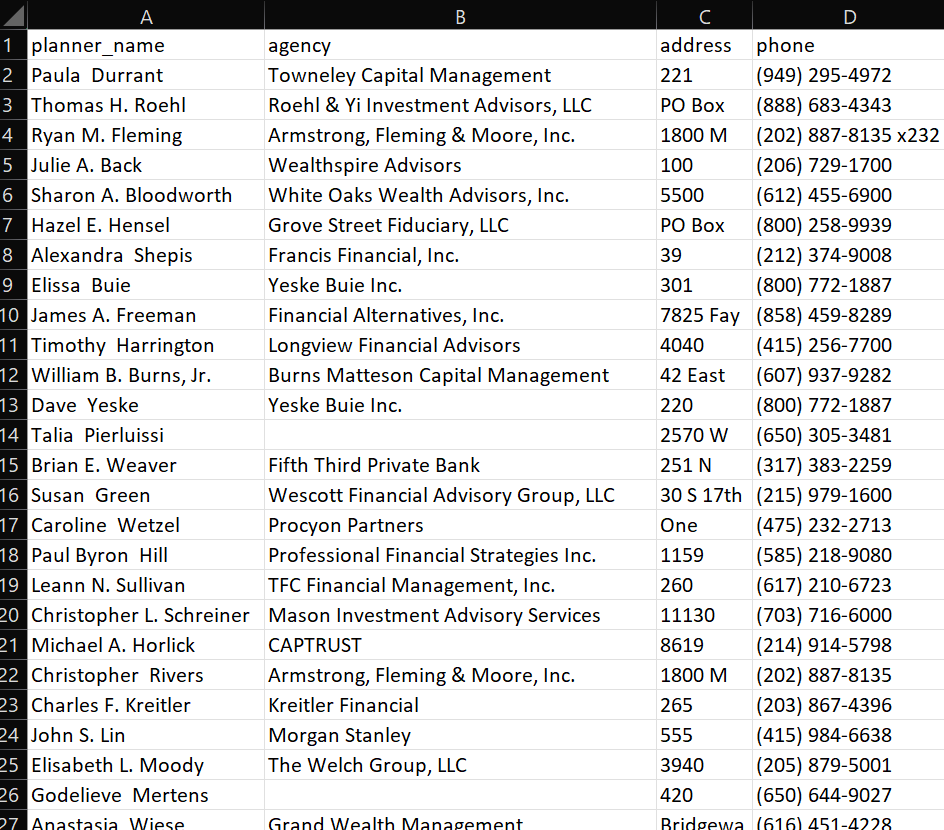
- The main fields that need to be scraped include:
- Planner name
- Agency name
- Business address
- Business phone number
- The custom search criteria of “investable assets over $1,000,000” must be included in the automation (using Playwright).
- The search results page is an “infinite scroll” page, so it must be dynamically scrolled by the script in order to display and collect all of the data.
- The results must be output to a properly formatted and cleaned CSV file.
Project Details
As indicated in the problem statement, the data to be scraped is from Financial Planners that manage “investable assets over $1,000,000”. Here we can see the script load the page, set the search criteria, extract the data, and continue to scroll the site:
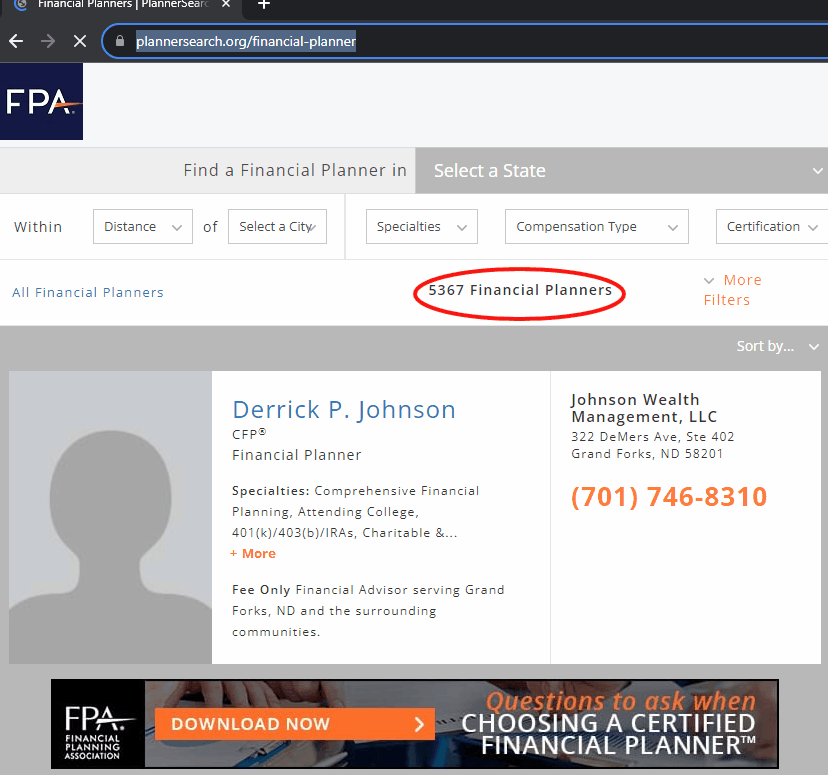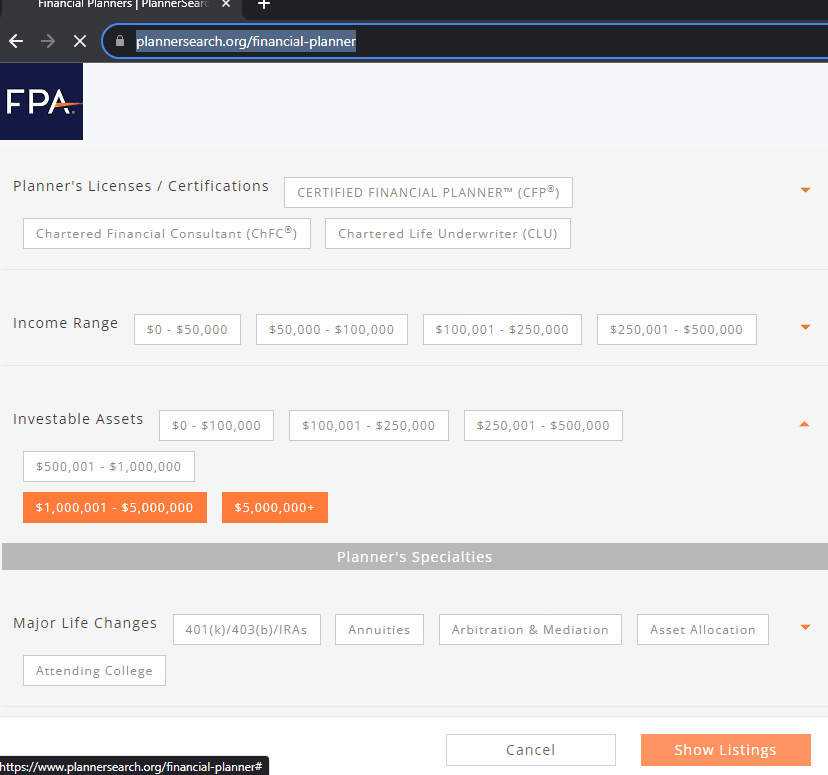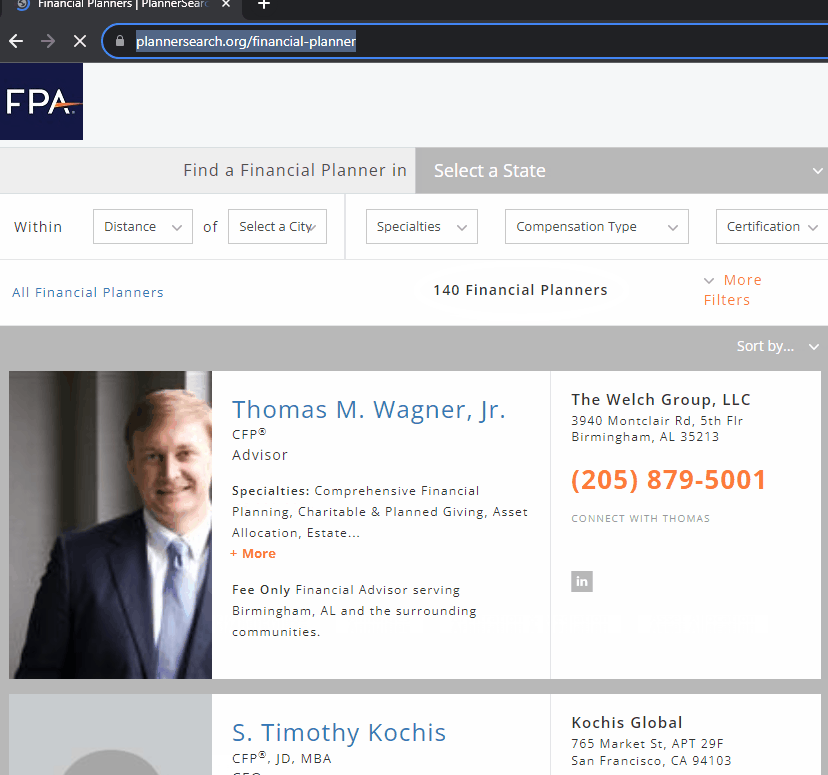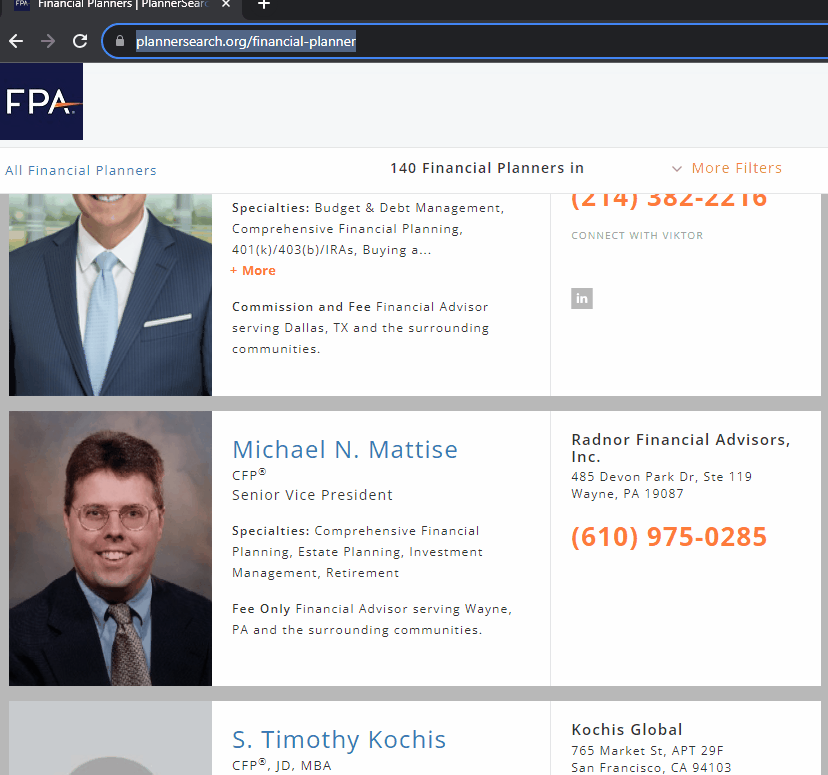
As this site has "infinite scroll", all of the data doesn't load unless the site is manually scrolled. In addition to that, the website's performance is pretty slow, with a number of pauses. This is the code we used to manage this issue:
# Infinite scroll to get all results
for x in range(1,10):
page.wait_for_load_state("networkidle")
sleep(2)
page.keyboard.press("End")
sleep(5)
Once the webpage data loaded, the fields from each listing are scraped and added to a DataFrame:
# Extract required data
html = page.inner_html('#search-results-container')
soup = BeautifulSoup(html, 'html.parser')
planner_panels = soup.find_all('div', {'class': 'row row-eq-height planner-panel these-panels'})
data = []
for panel in planner_panels:
row = {
'planner_name': get_text_or_none(panel, 'h2', 'planner-name'),
'agency': get_text_or_none(panel, 'h4', 'agency-name'),
'address': get_text_or_none(panel, 'address', 'agency-address'),
'phone': get_text_or_none(panel, 'span', 'advisor-phone')
}
data.append(row)
Once the script is run, we can see the final output in a CSV file: