Extracting Business Data from YellowPages
in Python
In this project we leverage Python with BeautifulSoup and pandas to extract business contact information from YellowPages within a specific category.
Project Overview
- Problem Statement: To accurately scrape business data from YellowPages. The businesses must be in the “Currency Exchanges” category, and be in the “San Francisco” region.
- Solution: My web scraping script will navigate to the correct URL, identify each listing that meets the criteria, and extract each of the required fields.
- Technologies Used: Python, Beautiful Soup, pandas
Key Features
- Error handling must be managed (ie: if a certain field doesn’t exist, the value for it will be blank, and it will not cause the script to crash)
- The main fields that need to be scraped include:
- Business name
- Business address
- Business phone number
- Business category
- Business website
- The results must be output to a properly formatted and cleaned csv file
Project Details
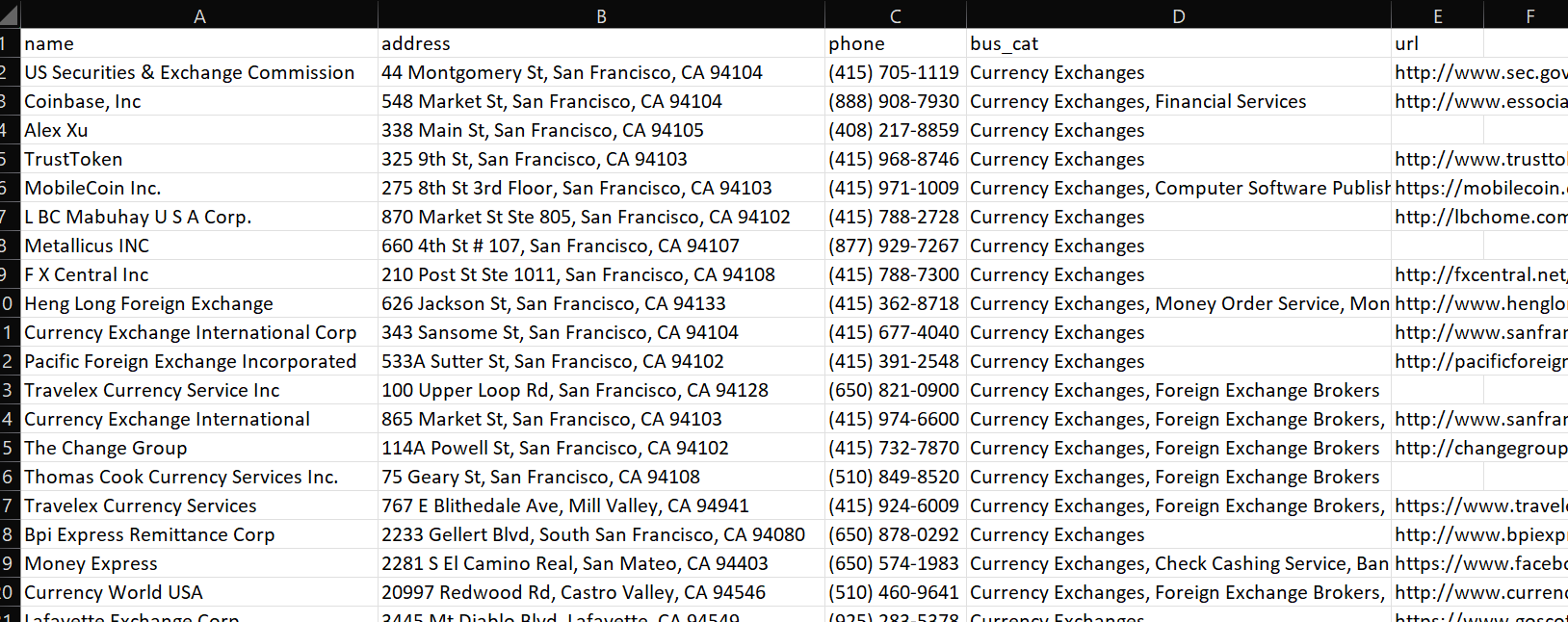
As indicated in the problem statement, the data to be scraped is from companies that are in the “Currency Exchanges” category, and be in the “San Francisco” region:

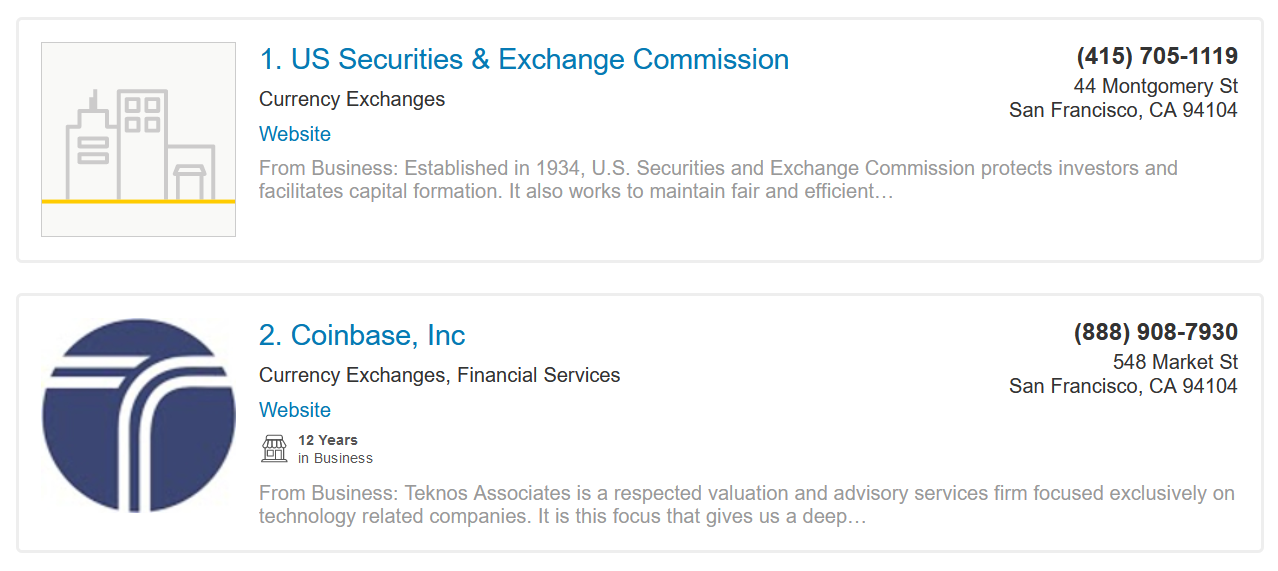
Here are a few examples of the results:
One major feature of this project is to handle any errors that result from a field not existing. The following function checks each field, and if it doesn't exist, it sets the value to be blank. If it does exist, it cleans the data and formats it properly:
# Check if element exists, otherwise set as None
def get_text_or_none(soup, tag, class_name):
element = soup.find(tag, {'class': class_name})
if element:
return ', '.join(child.get_text(strip=True) for child in element.children)
else:
return None
Once the webpage data is obtained, the fields from each listing are scraped and added to a DataFrame:
# Look through each result and extract data
data = []
for result in results:
try:
url = result.find('a', {'class': 'track-visit-website'}).get('href')
except:
url = None
row = {
'name': get_text_or_none(result, 'a', 'business-name'),
'address': get_text_or_none(result, 'div', 'adr'),
'phone': get_text_or_none(result, 'div', 'phones phone primary'),
'bus_cat': get_text_or_none(result, 'div', 'categories'),
'url': url
}
data.append(row)
Once the script is run, we can see the final output in a CSV file: